Case Study: Real-Time Competitor Price Intelligence Platform
Executive Summary
In the hyper-competitive gaming asset marketplace, pricing down to the cent determines who wins the sale. Wiresify engineered an automated, serverless competitor price tracking engine for an e-commerce client. By pairing a custom AWS Lambda crawler with an intelligent Make.com data processing pipeline, we gave the client real-time market visibility with $0 infrastructure overhead, ensuring they always maintain the most competitive prices on their website automatically.
The Challenge: Manual Scraping & Aggressive Rate-Limiting
The client needed to track price fluctuations across multiple regions (US and EU) on major peer-to-peer marketplaces. Doing this manually was impossible due to the sheer volume of server listings and rapid price changes.
Furthermore, building a traditional web-scraping infrastructure presented two major bottlenecks:
- High Infrastructure Overhead: Running 24/7 server instances (like traditional VPS) eats into profit margins.
- Anti-Bot Blocks & Rate Limiting: Target platforms quickly detect and block static data requests, stalling the data pipeline.
The Wiresify Solution: Serverless Intel & Intelligent Orchestration
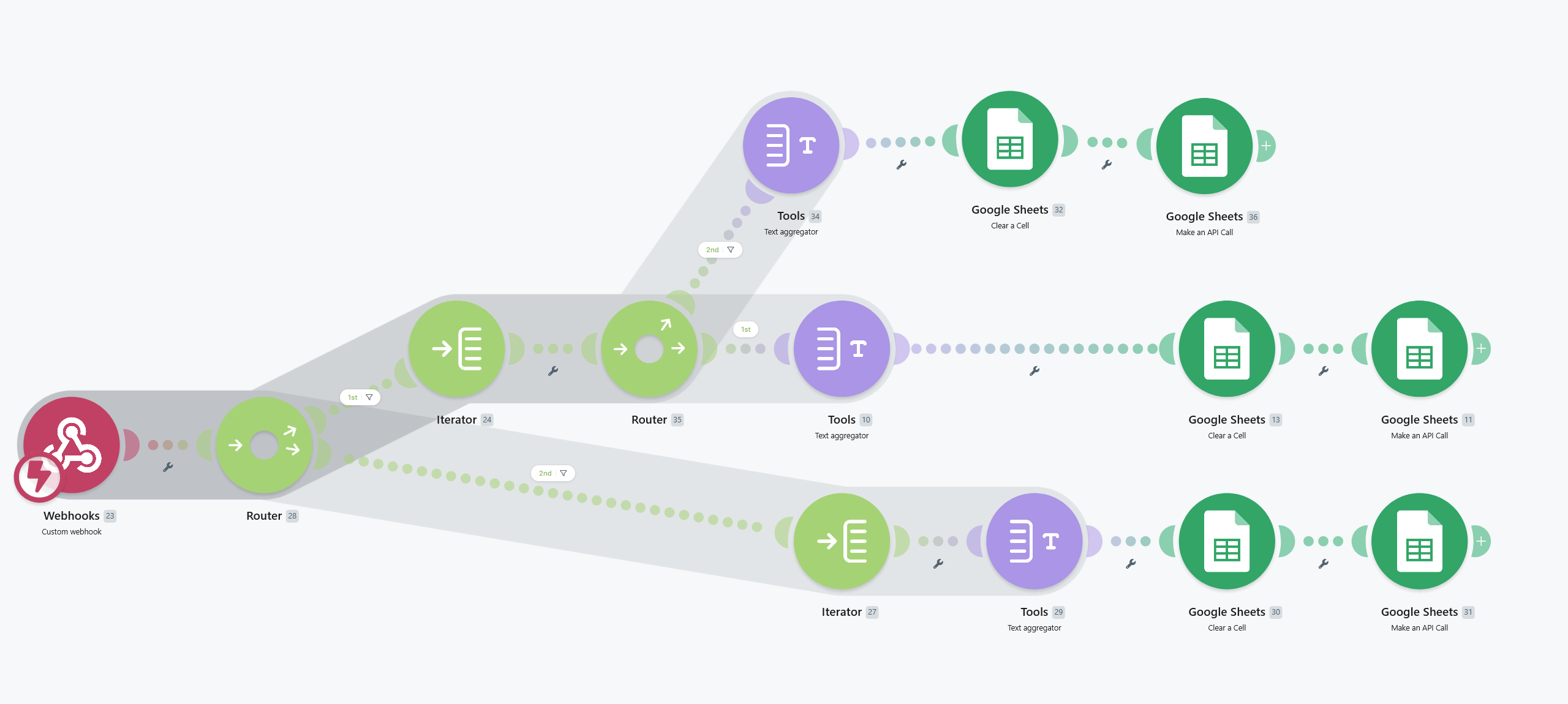
Wiresify designed a decoupled, highly efficient system that balances raw scraping power with smart, automated data workflows.
[AWS Lambda + Rotating Proxies]
│
▼ (Webhook JSON Payload)
[Make.com Router Engine]
├──► Region Filter: US ──► Data Aggregation ──► Sheet Sync
└──► Region Filter: EU ──► Stock Filter (≥1k) ─► Sheet Sync
1. The Serverless Edge (AWS Lambda + Rotating Proxies)
Instead of continuous servers, we deployed an on-demand crawler on AWS Lambda.
- Cost Efficiency: It executes entirely within AWS’s free-tier limits, resulting in a $0 monthly hosting cost.
- Anonymity: The script utilizes a rotating proxy network, swapping IP addresses with every request to cleanly bypass rate-limiting barriers without triggering security flags.
2. The Smart Automation Pipeline (Make.com Integration)
Once the raw market data is captured, it is shot via a custom webhook into an automated multi-branch processing workflow to filter out the noise.
- Regional Sorting: The pipeline instantly separates data arrays into dedicated US and EU operational tracks.
- Viability Filtering (Stock Verification): A critical business logic layer filters out dead listings. For example, in the EU track, the system checks competitor stock volumes. If a competitor has fewer than 1,000 units in stock, they are ignored—ensuring the client only benchmarks against actual market threats.
- Automated Sheet Overwrites: The pipeline automatically wipes the old rows (
A:C) and uses high-speed Google Sheets API calls to batch-write fresh URLs, server names, and lowest baseline prices.
The Results & Business Impact
“By moving from manual oversight to serverless automation, the client transformed their pricing strategy from reactive to predictive.”
- 100% Automated: Zero hours spent manually checking competitor pages or copying data into spreadsheets.
- Optimized Pricing: The client’s website reads directly from the synchronized Google Sheet, instantly updating storefront pricing to beat the competition.
- Zero Upkeep Cost: The entire scraping architecture runs effortlessly within serverless free-tier structures, requiring no active server management or monthly infrastructure fees.
- Data Accuracy: By filtering listings based on stock availability, the client avoids matching prices with fake or low-stock listings, protecting their profit margins.